世界杯买球并不只是对某支球队的情绪下注,而是在海量数据中寻求概率优势。在社交媒体碎片化信息的包围中,投资思维与娱乐消费常被混淆,真正想提升胜算的人需要重新审视信息获取、模型构建与风险控制的顺序,借助统计逻辑重建对赛事的理解。
数据框架比直觉更可靠。世界杯舞台的强队与弱旅差距已被转会市场迅速缩小,单靠传统“四大强队”经验做出下注决定,容易忽略对位细节。通过API或公开数据库抓取球队近三年的进球期望值、压力下传球成功率、定位球贡献,再结合不同场地、气候环境的数据滤镜,可构建更贴近现实的基础模型。尤其在淘汰赛,_xG_(expected goals)与_xGA_(expected goals against)的差异能预测某些防守稳固、但表面数据不亮眼的球队具备爆冷条件。

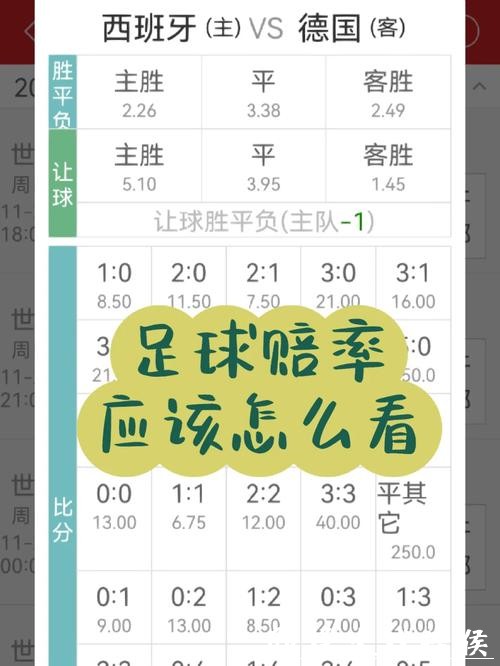
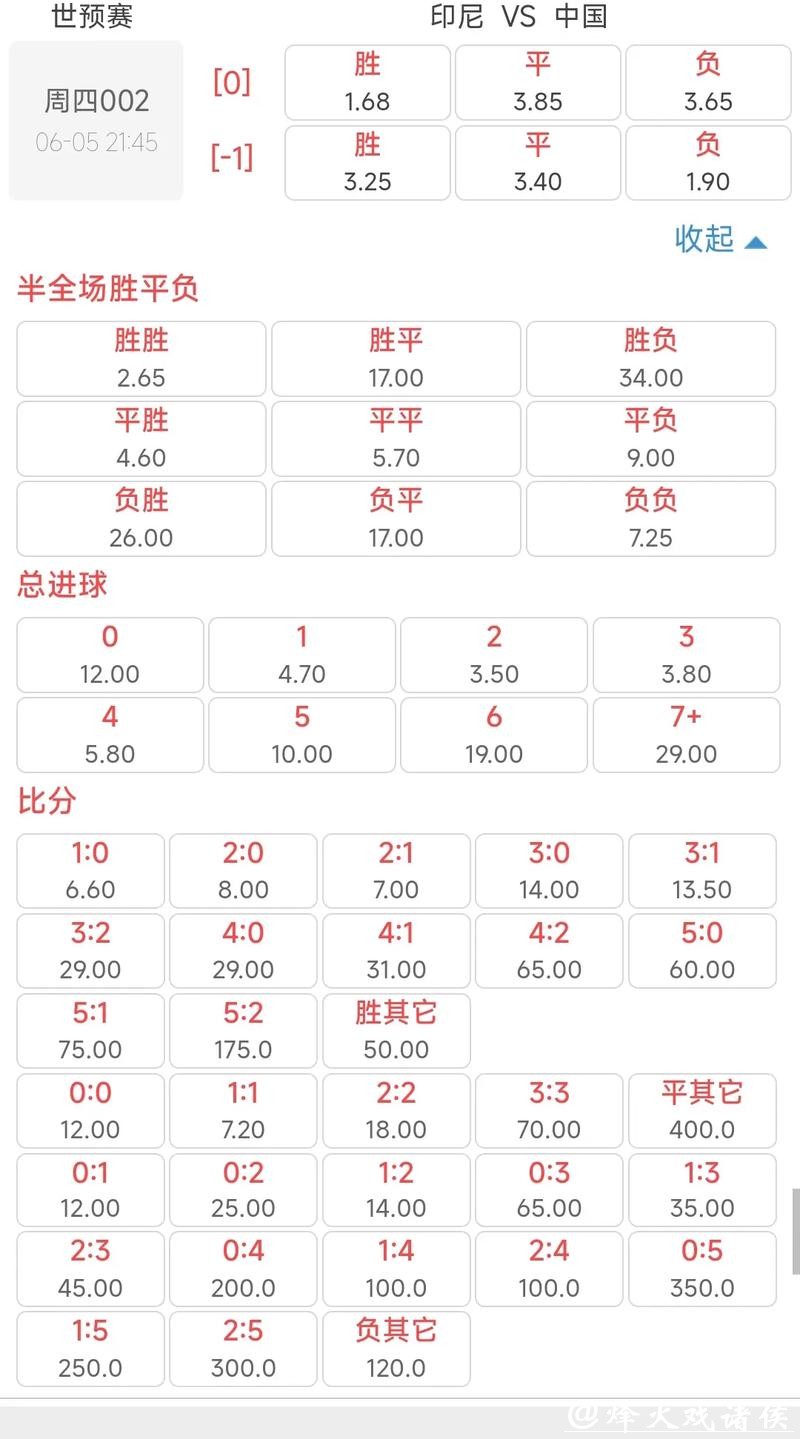
赔率是市场情绪的反映,但数据能拆解情绪偏差。多数平台会将热门球队的赔率下调以平衡资金池,导致真实概率被低估。通过贝叶斯更新方法,结合球队状态、伤病、行程疲劳等变量,我们可以计算自有概率,再与庄家赔率比对,从中找出价值投注。一个典型案例是2018年克罗地亚对阵阿根廷时,市场在首轮表现的影响下仍给阿根廷过低赔率,但克罗地亚的压力抵抗指数和反击效率在模型里明显高于阿根廷,最终3:0的结果就验证了数据洞见。
动态数据抓取帮助实时调整策略。世界杯期间,球队阵型随对手变化,训练中出现的微小伤情也会临时改变名单。通过订阅官方伤病信息、专业记者的更衣室报道,以及对技术统计的实时更新,可以在比赛前6小时内重新评估盘口,尤其是亚洲让分盘更易找到调整不够迅速的空间。实践中,笔者见过某届世界杯的小组赛第二轮,因中场核心未能首发,盘口仍按首发主力计算,结果对方很快陷入被动,早早失球,而对冲资金则获利退出。
机器学习模型提供超越手工分析的能力。在已有样本的前提下,利用梯度提升树或极端随机森林,可将天气、裁判执法尺度、球员出生年份等非线性因素纳入。模型训练需注意数据泄露问题,例如将同一场比赛中含未来信息的变量排除。此外,对世界杯这种低频事件而言,引入俱乐部层面数据以增强样本量,再通过迁移学习调到国家队场景,能显著降低过拟合。某些分析团队通过引入Elo积分波动、球员热区图等特征,成功识别2022年日本队在高压逼抢下的逆转概率。
资金管理是最终的生命线。即使数据模型能准确评估概率,若在单场比赛投入过高,也会因短期波动导致爆仓。常见做法是按凯利公式计算最优投注额,但考虑到世界杯的高波动性,建议采用_半凯利或更保守_的系数。将资金池分为基础策略、事件冲击、对冲保护三部分,可在爆冷时用现场现金流对冲,避免盲目追单。此外,在某些情境下,小比分投注或角球盘口能作为风险分散工具。

信息源的质量直接影响模型输赢。专业数据供应商如Opta、StatsBomb能提供高精度事件数据,与官方FIFA技术报告结合,能更好地理解战术趋势。与此同时,社交媒体和论坛虽噪声多,但在搜集小道消息时仍有价值,关键是验证其来源。建立自用的可信度评分系统,将不同渠道按照历史准确率加权,避免被错误谣言拖入不利决策。以往就有博彩公司利用假新闻制造赔率波动,数据玩家若没有多源交叉验证机制,很难在时间差中分辨真假。
可视化工具提升洞察效率。将球队进攻路线、球员触球热度、关键传球网络可视化,能让人在短时间内发现结构性矛盾。例如,若某支球队右路进攻依赖度极高,而对手左后卫防守数据出色,模型即可降低其进球期望。通过Python结合Plotly或Tableau制作动态面板,在赛前15分钟内更新图表,避免遗漏最新的首发调整。长期使用还能沉淀经验,例如识别某些裁判对身体对抗的判罚倾向与红黄牌盘口的关联。
案例: 利用多层数据解析黑马走势。以2014年哥斯达黎加为例,大量投注者因为其“死亡之组”身份而低估。若从预选赛和友谊赛数据入手,会发现其防守端的压迫指数高,门将反应能力卓越。结合比赛录像,可以看到球队刻意压制对手左路,迫使其回传。模型提示哥斯达黎加在被领先后仍能保持结构稳定,这直接解释了他们能击败乌拉圭、意大利的原因。数据不仅展示表面现象,还能揭示战术脉络,帮助玩家提前布局。
合规意识同样重要。在追求胜率的同时,必须理解各国对于体育博彩的法律框架,保持资金来源合法、记录透明。使用VPN或跨境平台可能触犯当地规章,同时,大量数据抓取也需遵守版权和API使用条款。建立合法账户、选择受监管的博彩公司,对长期策略而言意义重大。数据驱动不等于无风险,只有在合法合规的基础上,才能让分析成果最终转化为可持续的收益。